DevOps Is a Production Line
DevOps is not a tooling movement. It is the cultural import of a hundred years of production engineering into software — and reading it that way makes the discipline coherent again.
TL;DR. DevOps is not a tooling movement. It is a hundred-year-old production engineering tradition — Toyota Production System, Lean, Theory of Constraints — ported into software between 2008 and 2015 with new vocabulary. Software has a line from commit to production and a loop from production back to learning. Continuous delivery is just-in-time. Type systems and feature flags are poka-yoke. Blameless review is Deming. The technologies are negotiable; the principles are not.
Most introductions to DevOps start with tools. Continuous integration servers, container registries, infrastructure-as-code, Kubernetes, dashboards. This is the wrong starting point. DevOps is not a stack. It is a cultural inheritance from a hundred years of production engineering — a body of practice developed on factory floors in Detroit, Toyota City, and Cincinnati, then ported, almost line-for-line, into the software industry between 2008 and 2015. The vocabulary changed. The principles did not.
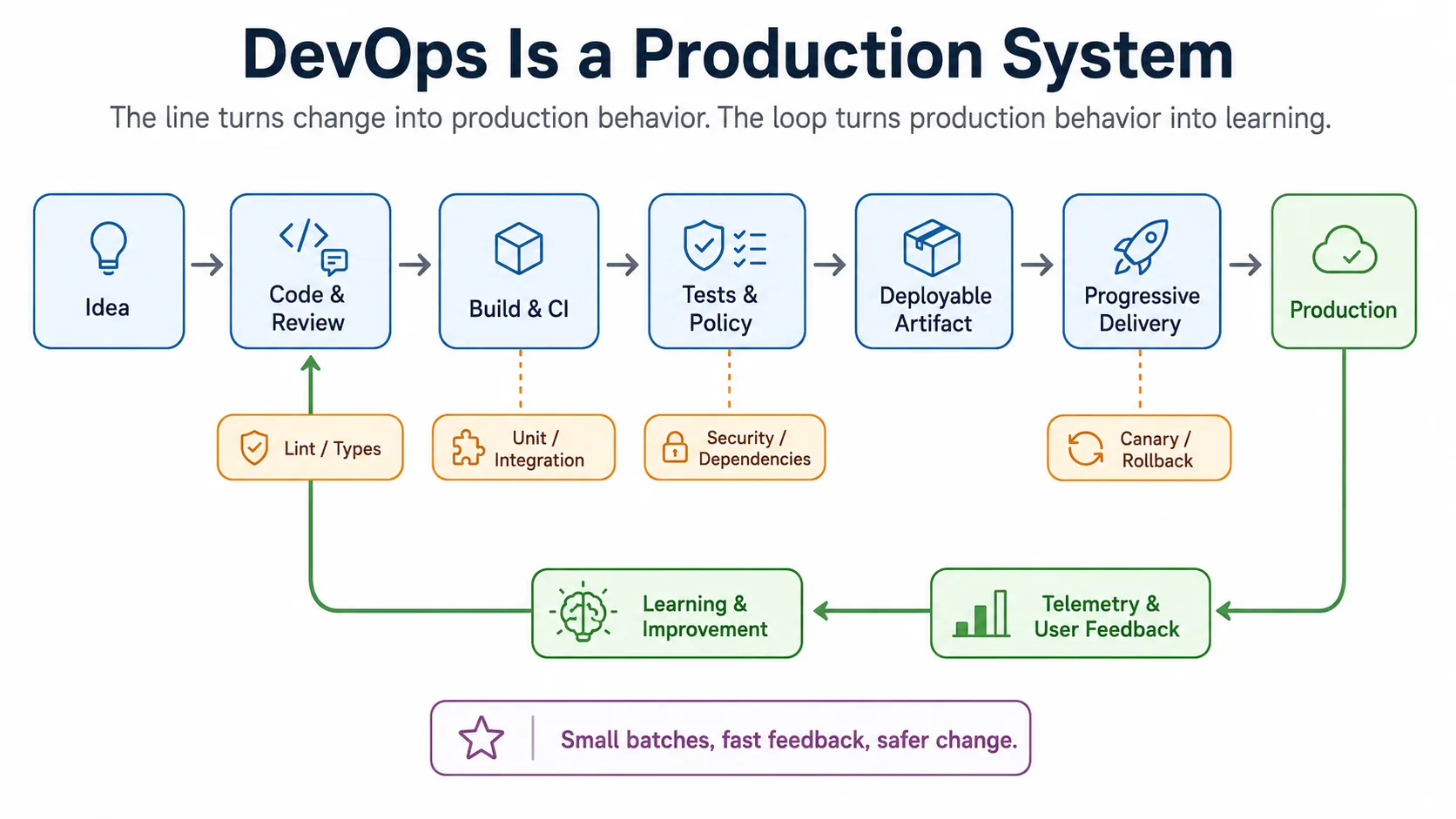
Read DevOps the original way and the moving parts become obvious. A software team has a line: the path a change takes from a commit on a developer’s laptop to a process running in production, serving a request. The line has stations: build, test, security scan, review, staging deploy, canary, production rollout. Each station has a check whose job is to catch a specific class of defect before it reaches the next station. The team also has a feedback loop: telemetry, error budgets, incident reports, and customer complaints flowing back from production to the people who change the code. Everything else in DevOps — every metric, every tool, every cultural practice — is a refinement of this two-part structure: the line that produces software, and the loop that tells the line how it is doing.
The lineage
The DevOps Handbook (Kim, Humble, Debois, Willis, 2016) opens by crediting three intellectual ancestors: the Toyota Production System, the Lean manufacturing movement that emerged from it, and the Theory of Constraints. These three bodies of work, developed in the second half of the twentieth century by Taiichi Ohno, W. Edwards Deming, and Eliyahu Goldratt respectively, defined modern production thinking. Software, as a discipline that ships every day to millions of users, eventually had to confront the same questions Toyota confronted in the 1950s: how to build something complex, repeatedly, without it falling apart on the way to the customer.
Toyota’s answer was the production system that turned a small post-war manufacturer into the global standard for quality. Two principles defined it. Just-in-time — produce only what is needed, only when it is needed, in the quantity needed. Jidoka — sometimes translated as “automation with a human touch,” the principle that any worker, on seeing a defect, can stop the line. These two principles inverted the prevailing American model of batch-and-queue manufacturing, where each station optimized for its own throughput regardless of downstream effects. Jidoka in particular made every worker responsible for quality at the source. The line is more important than any one station’s local efficiency.
Deming had been making the same argument, statistically, since the 1940s. His work in Japan — undertaken largely because American manufacturers refused to listen — laid the quality foundations Toyota built on. Deming’s central insight was that the vast majority of defects come from the system, not the worker. Blame is a category error. The right question after a defect is never who but what allowed this through. Goldratt, two decades later, formalized a complementary insight: any production system is constrained by exactly one bottleneck at a time, and optimizing anything except the bottleneck is wasted effort.
Software inherited all three. Continuous delivery is just-in-time production applied to deployable artifacts. Blameless post-incident review is Deming’s quality-as-system thinking applied to outages. DORA’s four key metrics — deployment frequency, lead time for changes, change failure rate, time to restore service — are the Theory of Constraints applied to the software supply chain. None of this is original. It is the same idea, ported.
The metaphor, made literal
A software production line begins with a change in a working tree and ends with that change running in production, observable by whoever needs to observe it. Stations in between vary by team, but a representative line for a serious software team looks something like this:
- A developer makes a change locally. Their editor and linter perform the first inspection.
- The change is committed. Pre-commit hooks catch a class of mistakes that should never reach the remote.
- The commit is pushed and a continuous integration job runs. Unit tests, integration tests, build, container image construction, security scans, and dependency analysis all happen here.
- The change becomes part of a pull request. Human reviewers inspect it. Automated reviewers — static analysis, coverage gates, format checks — inspect it in parallel.
- The change merges. A continuous delivery job builds the deployment artifact and stages it.
- The artifact is deployed to a non-production environment. End-to-end tests run against it.
- A canary release exposes the change to a small fraction of production traffic. Health checks watch for regression.
- The change rolls out to the full production fleet. Telemetry begins reporting on its behavior in real conditions.
Each of these is a station. Each station has a defined check whose job is to catch a defect of a particular character. Unit tests catch logic defects in a single function. Integration tests catch contract defects between modules. Security scans catch known vulnerabilities. Review catches design defects and missing context. Canaries catch behavior that survived test environments but breaks under real traffic. None of these checks subsumes the others. Each is responsible for one category of defect, and the line as a whole works because the catches compose.
The feedback loop runs the other direction. Production telemetry — error rates, latency, business metrics, customer complaints, incident reports — flows back to the team. The team uses that flow to tune the line: to add a check that would have caught the last defect, to relax a check that no longer earns its cost, to redesign a station that is creating bottlenecks. Without the loop, the line is open-loop and drifts. With the loop, the line is a closed-loop system that improves over time.
This is the same structure Toyota built. The vocabulary is different. The principles are not.
Quality is a property of the line
The hardest lesson manufacturing ever learned is that quality is a property of the production system, not of any single worker. American manufacturers in the mid-twentieth century treated quality as the responsibility of an inspection department at the end of the line. Defects were found there, reworked or scrapped, and the line kept moving. Toyota’s insight was that this approach produced worse quality at higher cost than the alternative: build quality in at every station, give every station the authority to stop the line, and treat defects that reach the customer as systemic failures rather than individual ones.
Software has the same lesson to learn, repeatedly. Most teams default to treating outages as individual failures. The on-call who paged. The developer who merged. The reviewer who approved. This is the inspection-department model wearing a different uniform, and it produces the same result: brittle systems where everyone is afraid of being blamed and nobody fixes the root cause.
The mature response to a production defect is to ask, structurally: what station should have caught this, and why did it not? If a security vulnerability ships, the question is not whether the developer should have known. The question is why static analysis or dependency scanning did not surface it before merge. If a regression appears in canary, the question is not whether the test author was sloppy. The question is what category of defect the test suite is not yet covering, and whether that gap is acceptable. The aim is never to blame an individual. The aim is always to harden the line.
This is what blameless post-incident review means. It is not a politeness convention. It is an operational stance. Blame focuses attention on the worker. Blamelessness focuses attention on the system. A team that consistently asks “what would have caught this” instead of “who broke this” ends up with a production line that gets harder to break over time.
The checkpoints
Every station on the line has a budget. It costs something to run — engineer time, build minutes, latency added to the path from commit to production — and catches something in return. Stations that catch a lot per unit cost stay on the line. Stations that catch little per unit cost should be replaced or removed.
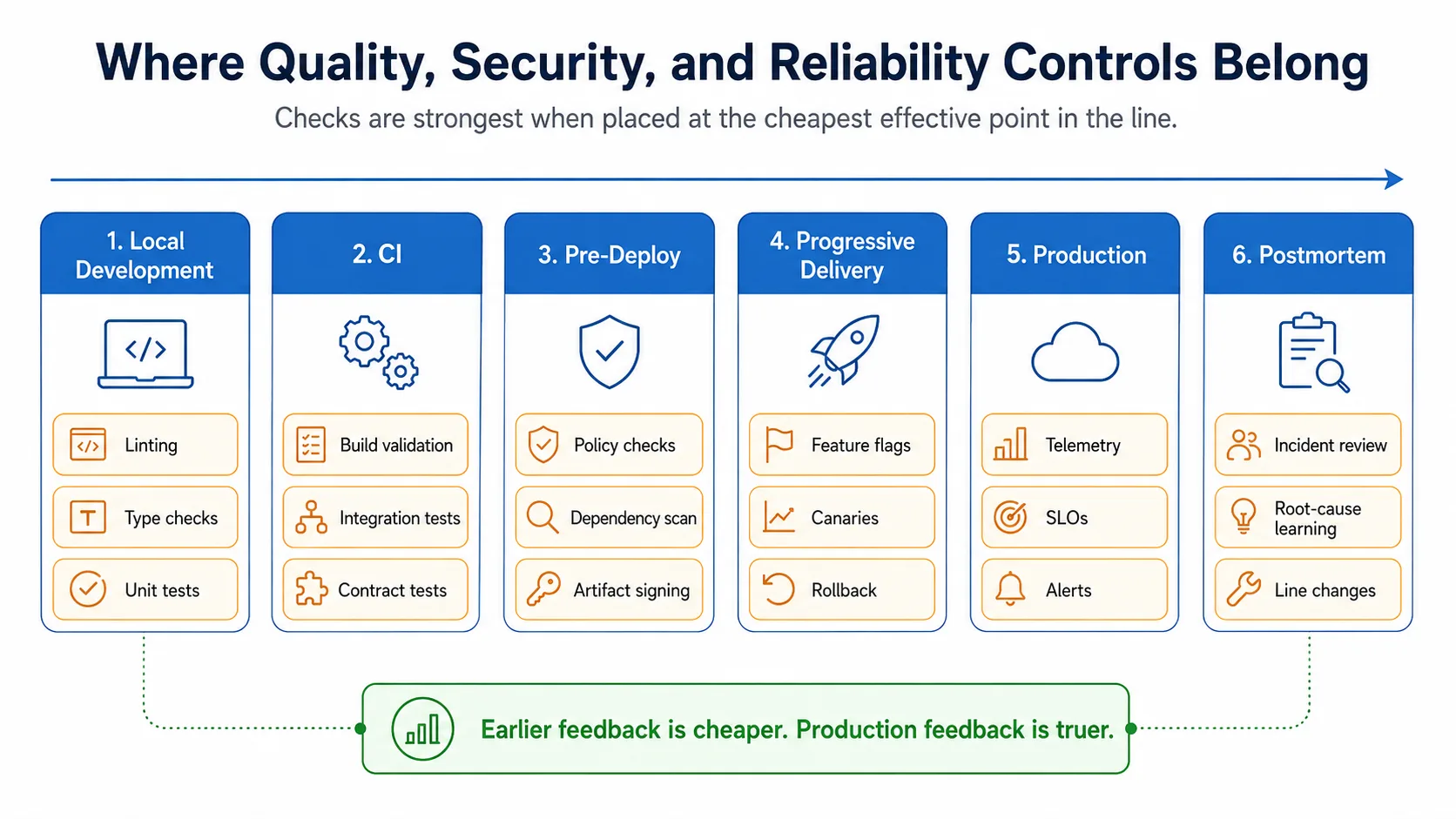
A type checker is a high-budget station. It runs in milliseconds, catches an entire category of defect at the lowest possible cost, and works for every change. A full end-to-end test suite is the opposite: expensive to maintain, slow to run, catches a different category of defect that earlier stations miss, but earns its cost only when those defects matter. A security scan is in between. Each station should be deliberate about what it catches and what it does not.
The mistake most teams make is to add stations reactively. A bug ships; the team adds a check. Another bug ships; another check. The line accretes inspections without anyone questioning whether they catch defects in proportion to their cost. The result is a line that is slow, expensive, and still does not stop the defects that matter. Toyota’s discipline here is exact: when a defect makes it through, the team asks what station could have caught it most cheaply, and that is where the check is added. The line gets denser at the right points, not uniformly.
Blind spots and learning
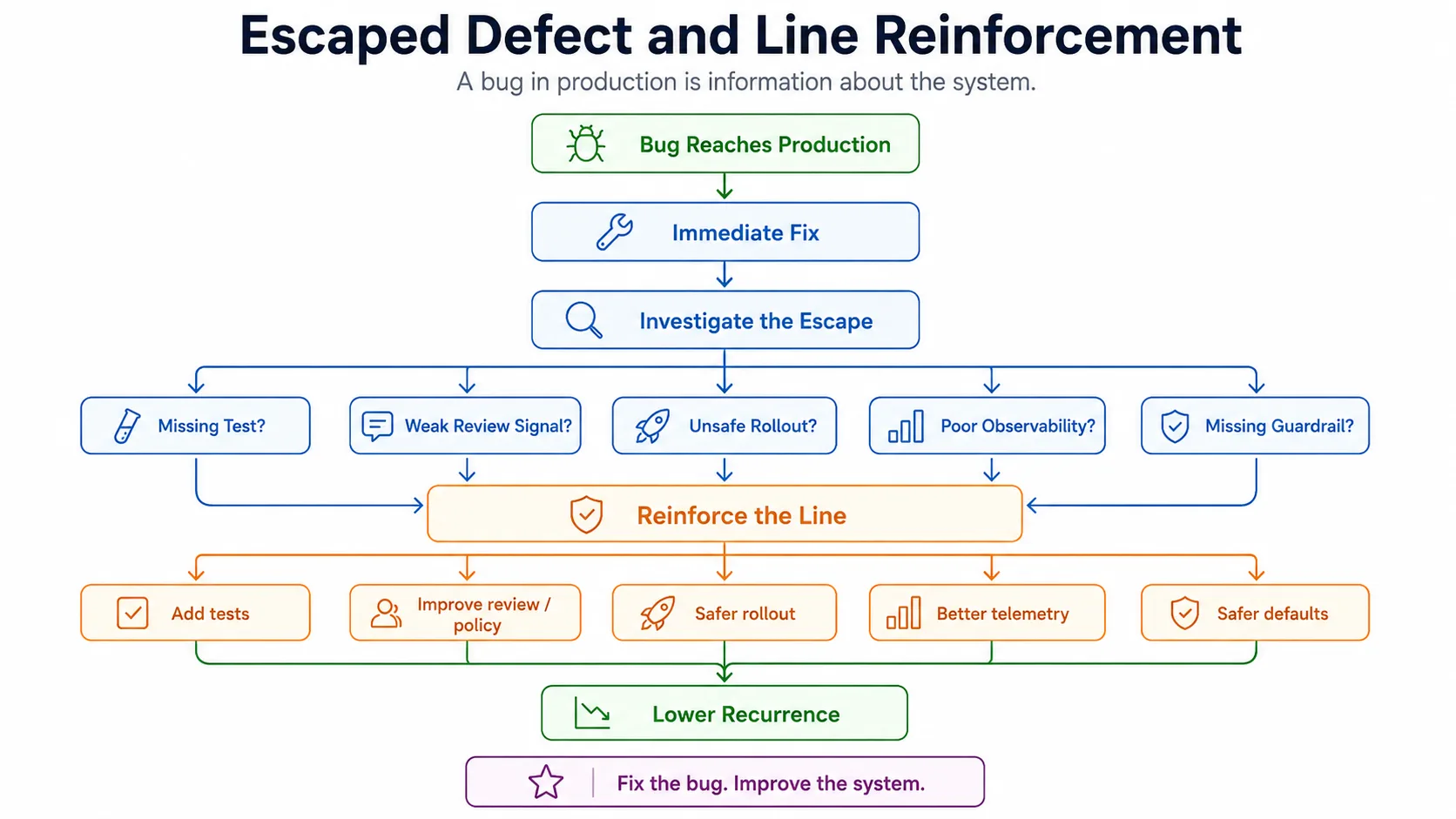
The most consequential property of a production line is what it does not check. A defect that ships is, by definition, a defect that survived every station on the line. The line had a blind spot. Toyota’s principle for this is poka-yoke — mistake-proofing — the deliberate design of the line such that the defect cannot occur in the first place, or fails so loudly it cannot be missed.
Software has its own poka-yoke patterns. Strong type systems make whole categories of bug unrepresentable. Feature flags allow a change to be merged and deployed but not activated, decoupling deployment risk from feature risk. Infrastructure-as-code with drift detection makes manual production changes immediately visible. Contract tests catch incompatibility between services before integration. Runtime guards — circuit breakers, rate limits, sandboxes for AI tool calls — fail loudly when an unexpected condition occurs. Each of these is a piece of poka-yoke. They do not catch defects. They prevent the defect from being expressible.
When a defect ships, the most valuable artifact of the response is not the fix to that defect. It is the new piece of poka-yoke that prevents the same class of defect from recurring. The fix is local; the poka-yoke is structural. Teams that ship the fix and skip the poka-yoke ship the same defect again later, just in a slightly different shape.
Single-piece flow
Toyota’s other foundational principle was to move from batch production to single-piece flow. Detroit in the mid-twentieth century built cars in large batches: stamp a hundred body panels, send them downstream, stamp a hundred doors, send them downstream. Defects in a batch were not discovered until the batch reached the next station, by which point the line was full of in-flight inventory and the defect had often replicated. Toyota’s single-piece flow inverted the model: build one car at a time, end-to-end, and discover any defect immediately, in context.
Continuous delivery is the software version of this argument. Trunk-based development with small, frequent commits is single-piece flow. Long-lived feature branches are batch production. Both technically work. Only one of them lets defects surface immediately, in context, by the engineer who can most cheaply fix them. Teams that move to trunk-based development with short-lived branches and frequent merges are not adopting a tooling preference. They are inheriting a manufacturing principle that has been validated empirically for sixty years.
The corollary is that batch sizes are a first-order property of production health. A team that ships once a quarter is operating in batch. A team that ships ten times a day is operating in single-piece flow. The two are not different points on the same continuum; they are structurally different production systems, and they fail in different ways.
The discomfort
None of this works without cultural support, and the cultural support is the hardest part. The andon cord — the cord any worker can pull to stop the line — only works in a culture where stopping the line is rewarded, not punished. A factory that punishes line stops produces fewer line stops but more shipped defects. The discomfort is real: pulling the cord costs throughput in the short term and earns better quality in the long term, and short-term thinking is the default of every organization that has not deliberately resisted it.
Software has the same problem under different names. A culture that punishes the engineer who pages on-call will not sustain reliability work. A culture that treats incidents as failures of individual judgment will not learn from them. A culture that prizes shipping velocity over quality of feedback loops will burn the people who try to keep the line healthy. None of these is a tooling problem. They are all problems of organizational reward structure, and they predate software by decades.
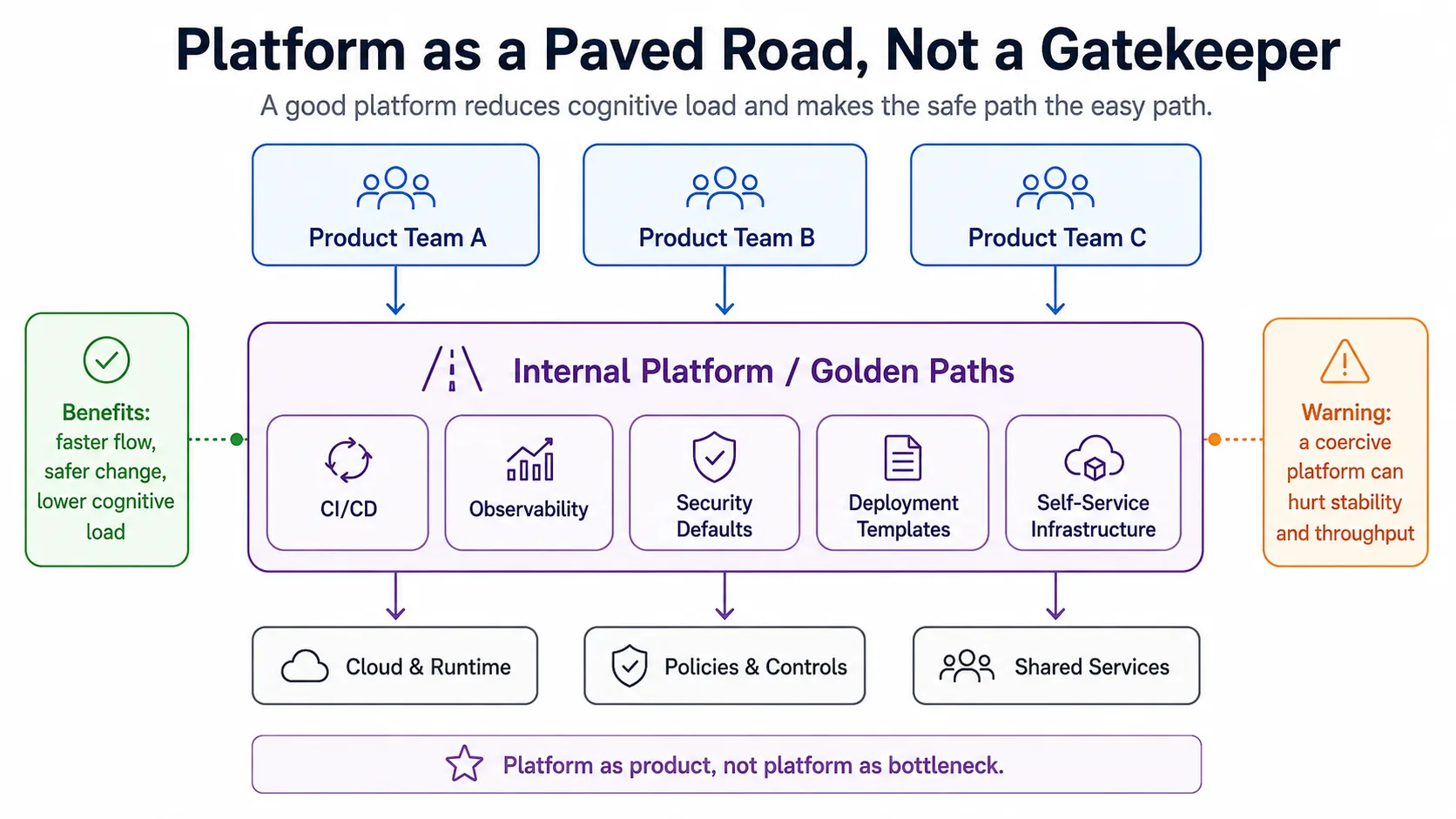
The DevOps practices that endure — trunk-based development, blameless post-incident review, error budgets, on-call rotations, paved roads, platform engineering as a service to product teams — are the ones that explicitly redesign the reward structure. They make the long-term work pay short-term dividends. Teams that adopt the tools without adopting the reward changes regress to the mean within twelve months.
What it adds up to
Read DevOps as a software-industry rediscovery of production engineering and the modern catalogue of practices becomes coherent. Trunk-based development is single-piece flow. Continuous delivery is just-in-time production. Type systems and feature flags are poka-yoke. Telemetry and DORA metrics are the feedback loop. Blameless post-incident review is Deming’s quality-as-system thinking. The platform team is a paved road. None of this is novel. All of it is a hundred years old, rebuilt with new vocabulary and shipped to a generation that did not know it had inherited a tradition.
The implication for adoption is direct. The technologies are negotiable. The principles are not. A team that adopts the tools without internalizing the principles ends up with a fast line that still ships defects, because the underlying production thinking was never imported. A team that internalizes the principles can choose almost any tools and still build a durable line.
Quality is a property of the system. Defects are systemic. The fix for a defect is the new piece of poka-yoke, not the patch. Small batches beat large ones. The feedback loop is as important as the line itself. Andon culture requires reward-structure changes. Every one of these is a manufacturing lesson. Every one of these is a DevOps lesson. They are, on inspection, the same lesson.