Fail Fast, Consolidate Faster
Modern organizations have become very good at trying new technology and much less disciplined at absorbing it. In the AI era, the risk is not experimentation itself, but experimentation without consolidation.
TL;DR. The problem with modern technology adoption is not that organizations experiment too much. It is that they institutionalize experimentation without institutionalizing consolidation. Virtualization produced VM sprawl. Cloud native produced platform fragmentation. Big data produced expensive initiatives that often failed to become durable business systems. AI is repeating the same pattern at a higher speed and with higher consequences. The answer is not to stop failing fast; it is to fail fast in bounded experiments, then standardize, govern, and retire technology faster than before.
Modern organizations have become good at jumping into the next technology wave. Virtualization promised better utilization and faster provisioning. Containers promised portability and deployment consistency. Big data promised analytical advantage. Cloud native promised speed. Now AI promises a new operating model for knowledge work, software delivery, customer service, analytics, and automation.
That first movement is not the problem. A company that cannot experiment with emerging technology is likely already falling behind. The problem starts after the first success. A proof of concept that was meant to answer a narrow question becomes a production service. A temporary integration becomes a dependency. A team-specific workaround becomes an undocumented standard. A platform exception becomes a platform pattern. Then the next wave arrives before the organization has cleaned up the last one.
That gap is assimilation debt: the space between what an organization has adopted and what it has truly absorbed. It has a lineage. In management research, Cohen and Levinthal’s classic work on absorptive capacity described a firm’s ability to recognize, assimilate, and apply external knowledge; Fichman and Kemerer later wrote about the assimilation gap in software process innovations. Assimilation debt is the operational version: the part that shows up as fragile pipelines, duplicated tools, half-owned platforms, and architecture nobody wants to retire.
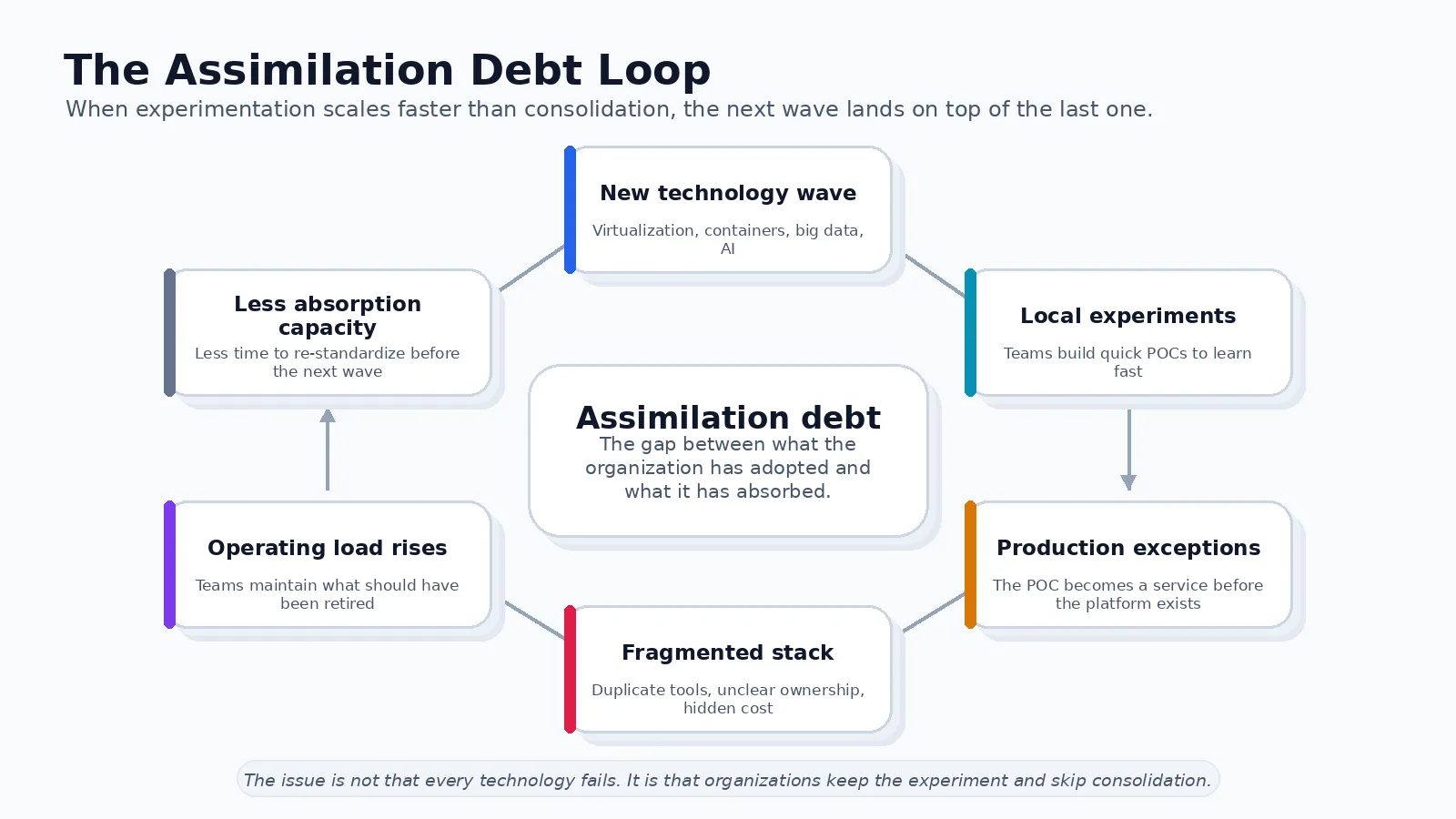
Failing fast, correctly read
The phrase “fail fast” is useful, but it has been flattened by repetition. In the Lean Startup methodology, the point was not to celebrate failure or to move recklessly. It was to shorten the build-measure-learn feedback loop so that teams could test assumptions before spending years building the wrong thing. Speed was meant to reduce waste, not excuse disorder.
Amy Edmondson’s work on intelligent failure sharpens the distinction. Harvard Business School summarizes an intelligent failure as an undesired result in new territory, where there is no way to know for sure whether something will work without trying it. That is very different from preventable failure in known territory. It is one thing to run a bounded experiment because the market, user behavior, or model capability is uncertain. It is another thing to push an immature architecture into production because nobody created a path from experiment to platform.
A proof of concept is not a smaller production system. It is a learning instrument. It should ask whether a workflow creates value, whether users can operate it, whether it can be governed, what it would cost to scale, and what should be retired if it succeeds. Too often, organizations answer only the technical question, then mistake possibility for readiness.
Adoption without absorption
Technologies do not simply lose stamina as they evolve. Many survive and mature. Virtualization did not fail. Containers did not fail. Kubernetes did not fail. In many environments, they became foundational.
The failure mode is more subtle. The technology matures, but the organization keeps the early disorder around it.
Virtualization is the classic example. It made servers easier to create, move, snapshot, and recover. But ease of creation also produced VM sprawl. IBM describes VM sprawl as the excessive and uncontrolled expansion of virtual machines, often caused by the fact that VMs are simple to create, easy to forget, and slow to decommission. The original promise was efficiency. The unmanaged outcome was clutter, waste, security exposure, and weak lifecycle discipline.
Cloud native repeated the same pattern at another layer. Containers, Kubernetes, service meshes, observability stacks, CI/CD tools, IaC frameworks, and managed services gave product teams enormous autonomy. That autonomy created speed, but it also created cognitive load. The CNCF Platforms white paper is explicit about why platform engineering emerged: enterprises enjoyed the value of autonomous DevOps teams, but needed to reduce the costs, security risks, duplication, and unclear ownership that came with each team solving infrastructure problems locally.
Platform engineering is not bureaucracy returning after DevOps. It is consolidation returning after experimentation — the organization saying: we learned enough from local variation; now we need common interfaces, self-service paths, security defaults, documentation, and retirement mechanisms.
Containers did not simply become another abandoned wave. The CNCF’s 2025 Annual Cloud Native Survey reported that 82 percent of container users now run Kubernetes in production and that 98 percent of surveyed organizations have adopted cloud native techniques. Maturation creates a new managerial obligation: standardize what worked, reduce cognitive load, and retire what no longer earns its place.
Big data showed the same dynamic in a different form. Data lakes, Hadoop clusters, streaming platforms, warehouses, and analytics initiatives promised better decisions. Some delivered. Many did not. A 2024 systematic literature review from ACIS notes estimates that 80 to 87 percent of big data projects fail to produce sustainable solutions. More importantly, it found that failures rarely stem from one cause. Technical issues such as data quality and integration were common, but so were skills shortages, cultural resistance, ethical and legal concerns, financial constraints, and methodological weaknesses.
The stack was not the whole problem; the organization around the stack was.
AI makes assimilation debt executable
AI compresses this entire cycle. Earlier waves took years to move from experiment to enterprise standard. AI capabilities can change in months. A pattern that looked reasonable last quarter may become unnecessary, expensive, or risky by the next model release or platform update.
That does not mean AI adoption is irrational. It means the assimilation problem is more severe. McKinsey’s 2026 work on AI trust and responsible AI maturity found that maturity is improving, but only about one-third of organizations report higher maturity in strategy, governance, and agentic AI governance. The imbalance is exactly the point: technical capability is moving, but organizational oversight is struggling to keep pace.
Gartner’s agentic AI forecast makes the problem even sharper. In June 2025, Gartner predicted that over 40 percent of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. Gartner’s Anushree Verma also warned that many agentic AI projects are early-stage experiments or proofs of concept driven by hype and often misapplied.
Those numbers do not mean AI is failing. They mean the adoption curve is steeper than the control curve.
The risk is larger than in previous waves because AI systems do not merely host applications or process data. They generate answers. They summarize documents. They recommend actions. They call tools. They may operate inside support workflows, developer environments, sales processes, compliance reviews, incident response, and internal knowledge systems. When the stack is incoherent, AI does not simply add another integration burden. It can amplify unclear ownership, bad data, weak permissions, and untested assumptions.
AI makes assimilation debt executable.
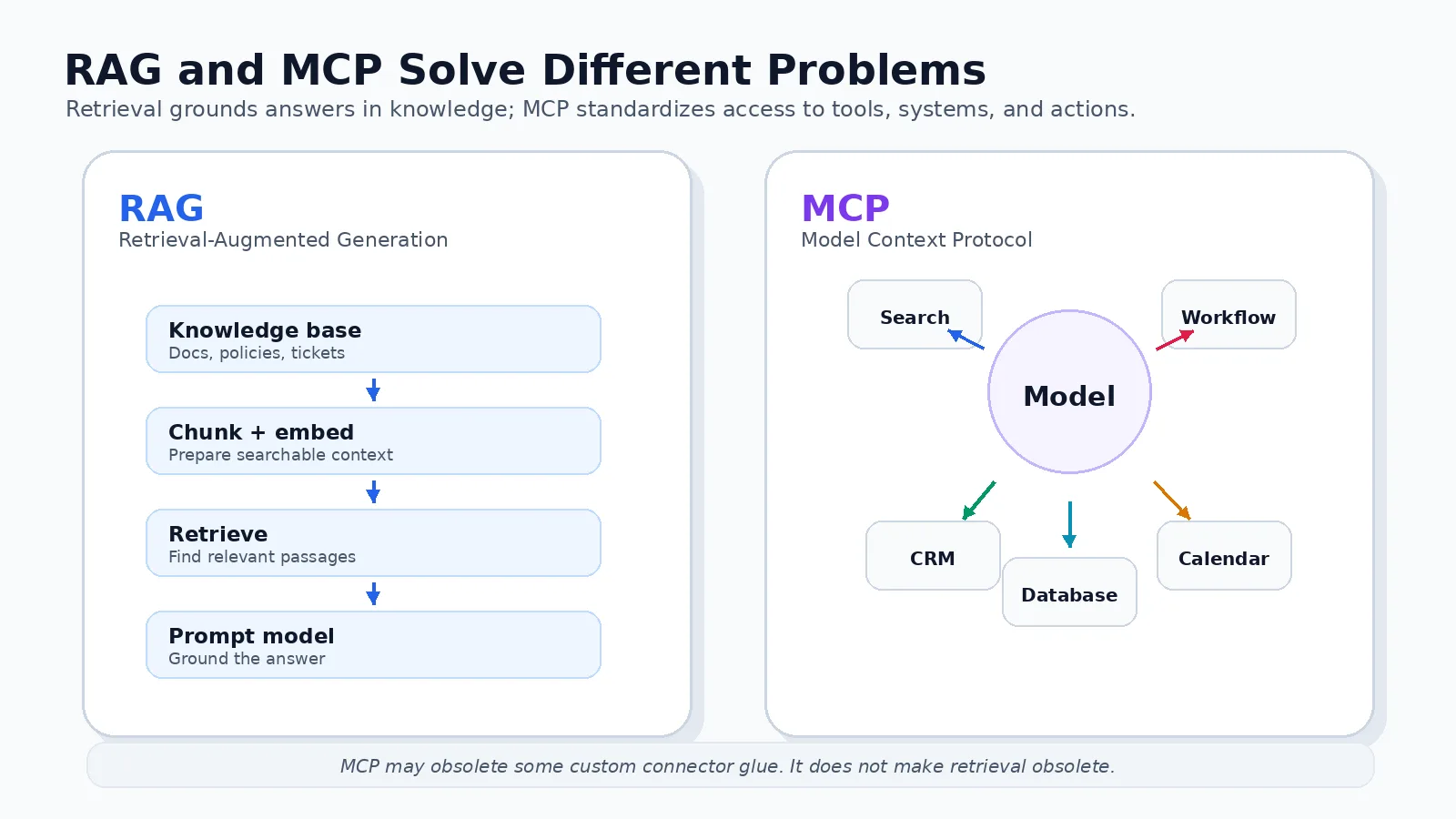
RAG, MCP, and architectural overstatement
The current conversation around RAG and MCP is a useful illustration.
Retrieval-Augmented Generation became one of the default patterns for enterprise AI because the logic was sound: models alone cannot know every internal policy, ticket, design document, product spec, or customer contract. Teams built retrieval pipelines so that documents could be chunked, embedded, indexed, retrieved, and inserted into prompts. RAG gave organizations a way to ground model output in external knowledge.
Now MCP has entered the conversation. The Model Context Protocol documentation describes MCP as an open-source standard for connecting AI applications to external systems: files, databases, tools, and workflows. OpenAI’s documentation similarly describes MCP and connectors as ways to give models new capabilities through remote servers and maintained integrations.
This is where the distinction matters. OpenAI’s retrieval guide describes retrieval as semantic search over data, powered by vector stores. Anthropic’s work on contextual retrieval still frames RAG as the typical solution for larger knowledge bases that do not fit inside the context window. MCP does not eliminate that need. MCP can expose a retrieval service. A vector database can sit behind an MCP server. A model can call that server as one of its tools. In that architecture, MCP has not killed RAG; it has changed the interface through which retrieval is accessed.
MCP threatens bespoke connector glue more than it threatens retrieval itself. Long context windows, managed file search, and standardized protocols may make some hand-rolled RAG stacks unnecessary. But retrieval remains a core architectural pattern when knowledge is large, changing, permission-sensitive, or too expensive to place wholesale into context.
Consolidation should not kill optionality
Not every experiment should be consolidated immediately. Some diversity is healthy. Some technology waves need a period of exploration before standards emerge. Premature consolidation can freeze the wrong pattern, trap teams in outdated assumptions, or suppress useful local learning.
The problem is not temporary diversity. The problem is diversity with no review mechanism. Adoption without a kill switch. Every team keeping its own connector, vector store, prompt framework, workflow engine, or observability stack because no one has the authority, incentive, or time to decide what should become standard and what should disappear.
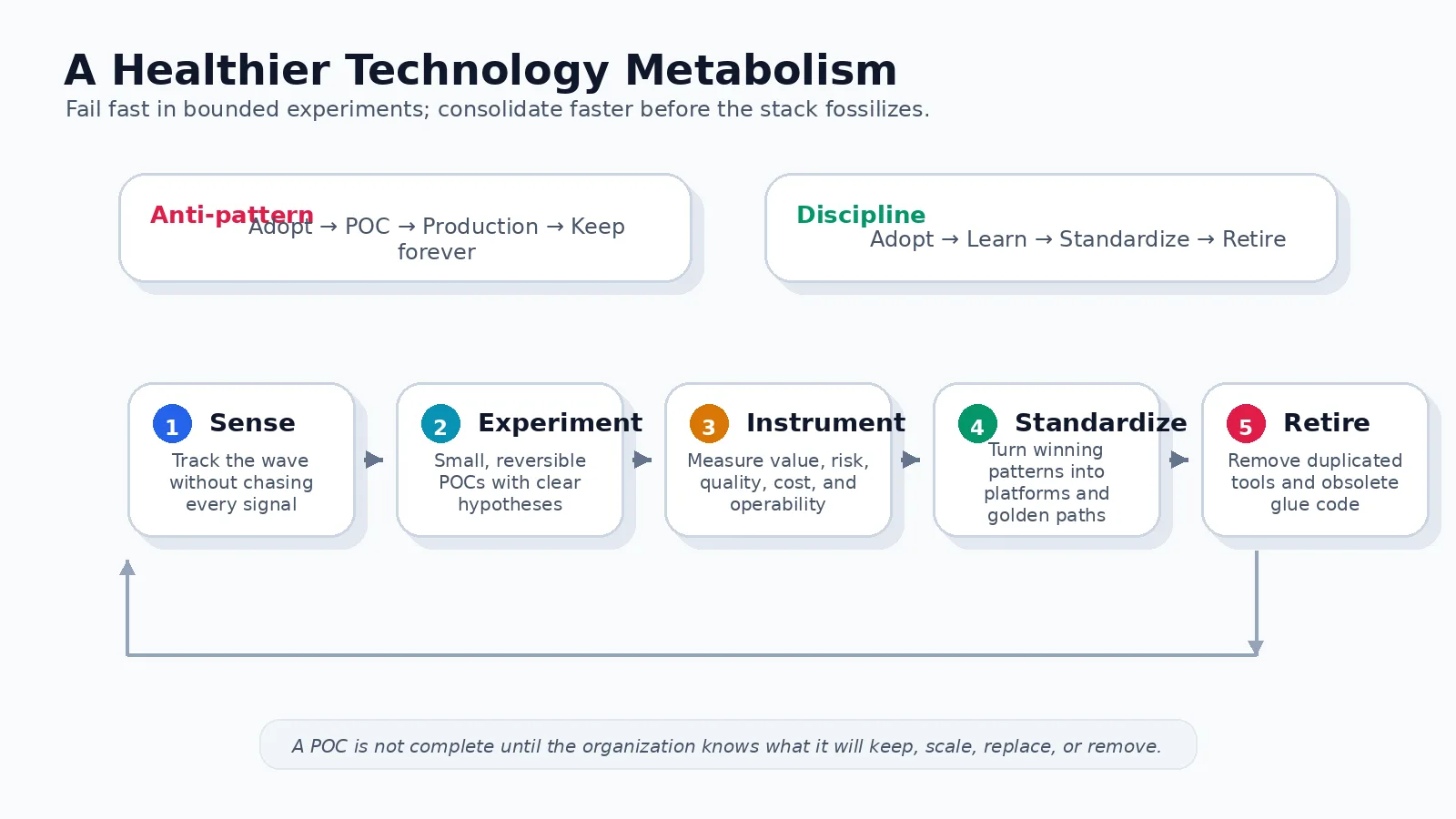
The goal is a better metabolism. Sense what is changing. Run small experiments. Instrument them. Compare outcomes. Standardize what works. Retire what no longer works. Then repeat.
What it adds up to
A technology organization needs two speeds. The first is exploration: testing ideas before they harden into industry convention. The second is absorption: converting successful experiments into governed infrastructure and retiring the rest before they become permanent complexity.
The first speed gets celebrated. The second is what makes the first sustainable.
Failing fast is not enough. Organizations must also consolidate faster — asking, after every successful experiment: what becomes reusable, what becomes governed, what gets deleted. Retirement is an architectural activity. Evaluation, access control, observability, and cost controls are part of the product, not afterthoughts.
The experiment is not done when the demo works. The work begins there.